
題圖來自視覺中國
2000年5月,上海第一家星巴克落戶淮海路力寶廣場,雖然這並不是星巴克在中國的第一家店,但在隨後的20多年裏,上海迅速成為全球星巴克門店最多的都市,現在幾乎是曾經排名第一的都市——韓國首爾的2倍。
2014年,首爾284家,上海273家。這是首爾最後一次成為全球星巴克最多的都市。
2015年,首爾312家,上海365家。上海超過首爾,至今仍不斷重繪著星巴克都市規模的新紀錄。
截至目前,上海已有884家星巴克在營,但我們幾乎從曲線上看不到任何减速的迹象,反而是越開越快。根據極海品牌監控的數據,僅2020年,上海就新增了86家星巴克,好像這樣的增長是沒有盡頭的。

數據來源:極海品牌監控
上海的星巴克飽和了嗎?
真的沒有盡頭嗎?這在投資市場是一個嚴肅的問題。
規模預測是投資決策中的關鍵一環,尤其是中後期項目。這一階段,品牌已經用財務資料論證了單店盈利的可行性,跨過了從0到1的“驚險一躍”,後期的估值主要落在了規模的增長上,囙此如何更好的預測品牌未來發展規模尤為關鍵。
傳統研究方法主要從“需求端”和“供給端”對市場進行折開分析,優點是邏輯簡單直接,缺點是數據獲取困難且信度存疑。
以最基礎的人口數據為例,首爾都市圈人口2300萬門店517家,上海人口2400萬門店884家,是什麼導致了門店數量的巨大差异呢?其中必然要用到更加精細的人群畫像標籤,但人口數據不會直接告訴你有多少人喝咖啡,喝多少咖啡,喝什麼咖啡,關聯性人口標籤質量往往也很難達到預期,很可能連目標人群規模都難以達成共識。
但門店規模的預測又有其特殊性:一個都市的地理空間是有限的,滿足選址條件的地段是稀缺的,門店之間的距離也是有極限的,不可能無限加密,借助都市大數據,我們至少可以預測其中短期門店規模的天花板,從而判斷品牌潜在的增長空間和方向。
上海的星巴克都開在哪了?
要預測規模,我們首先要把這個城市能開店的地方都找出來。
在極海規模預測系列的上一篇文章《如何預測下一家喜茶開在哪裏?》中,我們用“共生品牌”策略為品牌方提供了一種挖掘潜在選址點的算灋,本文將從投資者的視角,將這一算灋運用到都市門店規模上限的預測中去。
我們把門店分佈具有較强一致性,在一定範圍內同時出現的概率較高,在選址策略趨於一致的品牌稱為“共生品牌”。共生品牌的本質是擁有類似客群的品牌最終也會在位置上趨同,就像麥當勞和肯德基的關係一樣。
依託我們在地理空間算灋和都市大數據上的積累,我們將上海的星巴克咖啡依次與品牌庫裡的500+連鎖品牌的地理位置進行關聯性計算,得到其關聯强度的排序如下:

*受篇幅限制,僅顯示關聯度具有統計學意義的前十個品牌。
我們根據共生品牌的位置分佈和關聯度為基礎,在地圖上加權賦值生成潜在選址點的熱力圖,並根據熱力值圈出了424個聚客區。

85%的星巴克在營門店都落在了我們標識的聚客區上,雖然我們可以通過擴大邊界囊括更多的點,但這也會讓聚客區顯得過於寬泛,失去實際意義。在實際的應用中,80%以上的預測率都屬於可接受的範圍。

*綠色點星巴克實際門店位置,虛線框為預測的聚客區域。
這裡需要額外注意的是,投資者和品牌方在選址上的思維路徑有所不同,需要區別對待。
對品牌方而言,他們需要跑十幾點比特才能確定一個選址,所以可以接受盡可能多的預測。但投資人往往沒有機會一個個點比特去核實,所以必須要設定一些的規則,對這些聚客區進行篩選。
常用的篩選規則主要包含以下幾類:
(1)聚客區成熟度。根據聚客區的商業成熟度對其進行分級,排除成熟度較低的聚客區。
(2)品牌門店特性。根據品牌門店對租金、面積、物業條件、所處位置的特殊需求,通過疊加相關要素圖層,排除不符合品牌選址邏輯的聚客區。
(3)聚客區競爭度。根據聚客區的競品分佈對其進行分級,避免品牌門店進入優勢品牌聚集、競爭壓力過大的區域。
星巴克門店對物業本身的要求並不高,且處於咖啡茶飲行業的第一梯隊,我們使用共生品牌的數量及關聯强度綜合衡量聚客區的成熟度,排除掉部分質量較差的聚客區後,剩餘的253個聚客區仍能覆蓋80%的現有門店,篩選後的模型仍具有較强的預測性。
上海的星巴克到底有多密?
現在我們已經知道了星巴克門店的潜在選址範圍,决定規模的關鍵就在於他在這些地方還能開多密。
一個聚客區對應的不一定是一家門店,一些商業發達的都市覈心聚客區往往會連成一片,擁有多家星巴克。在上海,最大的一個聚客區上就分佈了59家門店。
我們將這些聚客區內,共生品牌門店數量為X軸,星巴克門店數量為Y軸,繪製成散點圖,並用線性回歸方程進行擬合。在一個較高的信度下(R²=0.94),平均每3個共生品牌周邊就可以支撐一家星巴克門店。
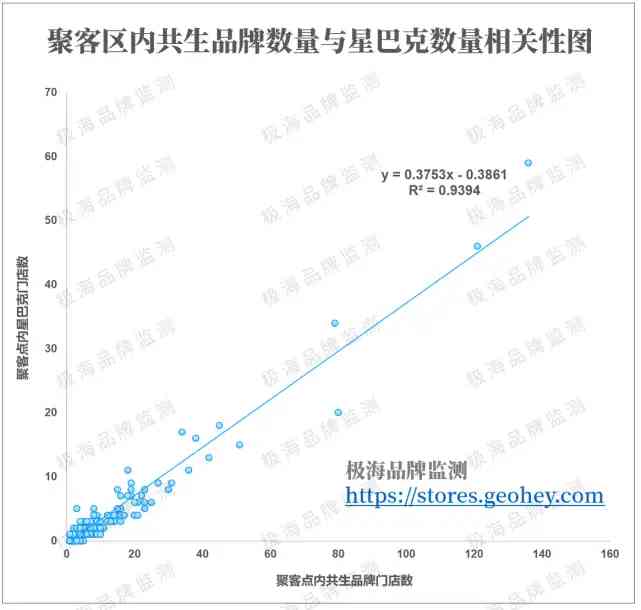
這樣驚人的擬合程度一度令我感到懷疑,懷疑是不是數據做錯了。因為同樣的嘗試我也做過喜茶,但擬合度僅有0.7上下。其中的關鍵在於,喜茶的門店擴張並不充分,難以構建有效的數據關聯。而星巴克在上海的擴張已經趨近於飽和,數據的規律性也體現的更加明顯。
這種規律性從某種程度上反映了品牌擴張最終的“穩態”,關聯性越强,市場越飽和。但他還不能用於推算市場規模,尤其是新興品牌的預測上,因為我們很難篩選出哪些才是飽和的聚客區,從而用他們來建構模型預測未飽和區域的門店規模。
還是把思路拉回門店密度這個概念上來——同樣的區域,門店越密集門店規模也就越大。
我們也對“加密門店占比”這一密度名額進行過深入的剖析。我們將最早開在聚客區內的門店稱之為“覈心門店”,將之後開在開拓型門店周邊的門店稱之為“加密門店”。我們只要預估出未來加密門店的占比,就可以根據聚客點數量推算出門店規模了。

以上圖為例,圖中共有2個聚客區(相連的藍色區域),覈心門店數量等於聚客點數量也是2個(紅色點),圖中共有3家門店,開拓型門店占比2/3≈67%,加密型門店占比為1-37%=33%。囙此,要反推門店總數,就要用聚客點數量/(1-加密型門店占比),如2/(1-33%)=3就可以了。
先來看看上海星巴克門店密度的規律。
我們按不同年份繪製了星巴克歷年的密度曲線。隨著星巴克門店從2015年的365家擴張到2021年的884家,加密門店的占比也從19%提升到65%。
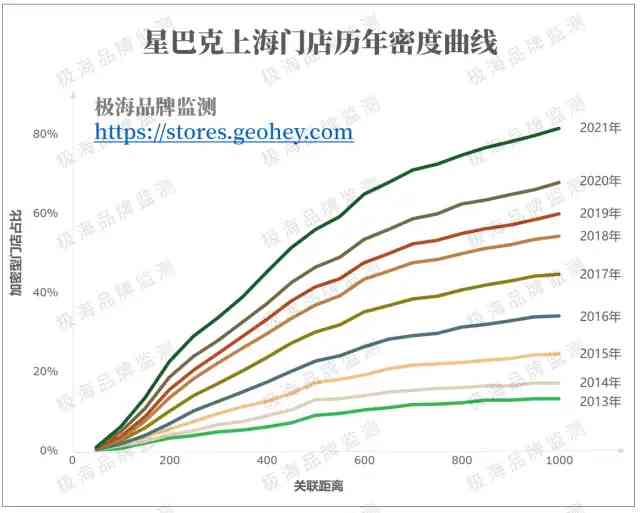
*以600的關聯距離為准取值。
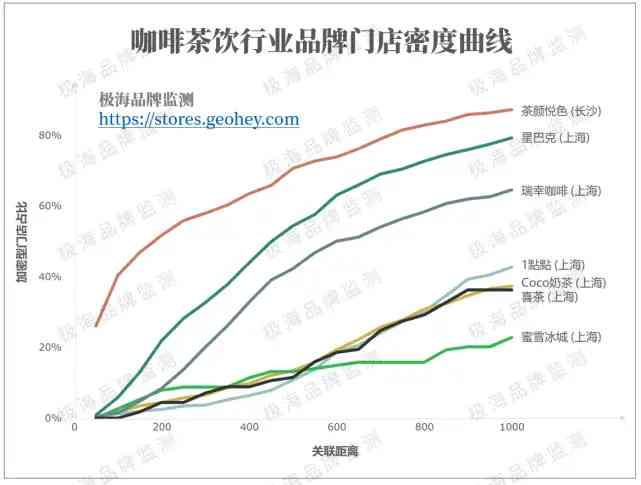
這是一個什麼水准?就咖啡茶飲行業來說,上海找不出第二家比星巴克更加密集的品牌,瑞幸咖啡634家門店,加密門店也占比僅50%。唯一可以與之相提並論的就是以高密度開店著稱的長沙茶顏悅色,占比達74%。
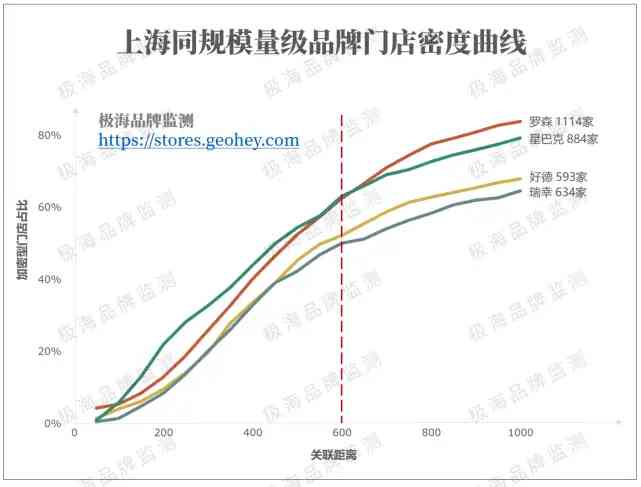
在門店規模上,唯有最密集的業態——便利商店行業可與星巴克相提並論。羅森1114家門店,加密門店占比與星巴克相仿達63%。不得不感歎,星巴克在上海真的就像是便利商店一樣普及。
綜上所述,我們判斷中短期內上海星巴克加密門店占比上限在70%~75%之間。
預測上海星巴克門店市場規模:1020~1189家
有了聚客點(253個)和加密型門店占比(70%~75%)兩個數據,我們可以的預估出星巴克中短期在上海的門店規模在253 /(1- 70%)≈843到253 /(1- 75%)≈1012家之間,加上之前不在我們預測範圍內的20%的門店(177家),修正後的門店規模在1020家到1189家之間,為方便後續表述,這裡統一取值1100家。
現時上海星巴克在營門店884家,飽和度= 884/1100≈80%,已經非常接近飽和。即使是在非常理想的情况下,按現時80家/年的開店速度,在星巴克的選址策略和上海市城市規劃不發生重大調整的前提下,星巴克在上海的快速擴張最多也只能維持2年多。
我們認為,在實現2022財年末6000家門店(大陸地區)的目標後,預計上海2023年的門店擴張速度將大幅放緩,星巴克在上海的門店策略即將迎來有一個新的調整期。

寫在最後
不同於傳統測算方法,我們從選址可能性的角度,運用共生品牌尋找潜在選址點,通過同類比較預測門店密度,對品牌中短期規模的上限進行了預測。思路和方法雖然比較清晰,但具體執行下來要考慮的種種參數依然是一項艱巨的任務,其中涉及的細節較多,篇幅有限無法進行詳細的說明。
這裡我們僅僅使用了上海星巴克的數據作為案例,同樣的方法論也可以複製到其他城市,就可以預測星巴克在全國的規模。
評論留言